Web
Sites Sharing IP Addresses: Prevalence and Significance
Benjamin
Edelman - Berkman Center for Internet
& Society - Harvard Law School
[
Background - Raw Data - Analysis
- Conclusions - Support & Extend This
Work ]
|
Abstract More than 87% of active domain names are found to share their IP addresses (i.e. their web servers) with one or more additional domains, and more than two third of active domain names share their addresses with fifty or more additional domains. While this IP sharing is typically transparent to ordinary users, it causes complications for those who seek to filter the Internet, restrict users' ability to access certain controversial content on the basis of the IP address used to host that content. With so many sites sharing IP addresses, IP-based filtering efforts are bound to produce "overblocking" -- accidental and often unanticipated denial of access to web sites that abide by the stated filtering rules. |
Related Projects |
This document discusses the prevalence of certain web server configurations and the effects of these configurations on systems used to restrict access to content on the Internet. Before proceeding with data analysis, some readers may want to review the terminology used and the relevant background circumstances.
IP Sharing
Web sites are hosted on web servers, computers running specialized software that distribute web content as requested. Each server typically has a single IP address, a unique numeric identifier assigned to no other computer on the entire Internet. (To the extent that a single server uses multiple IP addresses, it is for purposes of this document effectively multiple servers -- for its distinct IP addresses could be filtered separately and independently by those who seek to restrict access to web content.) Web sites are typically associated with domain names -- textual strings like "yahoo.com" that are easier for users to remember than numeric IP addresses.
Under the initial version of the HTTP specification that defines the transfer of web content, web servers receive from web browsers only the name of the requested file, without any supplemental information as to the web site hosting that file. "Give me the file /index.html," a browser might say to a server; if the server happened to host multiple web sites, each with a file of that name, the server could not know which file to provide. As a result, under the initial version of HTTP, each domain name with web content needed its own IP address. If a server was to host several web sites, each with its own domain name, the server would need that many IP addresses, and it would provide the appropriate files by tracking which IP address was the recipient of which requests.
In principle as many as 4 billion IP addresses might be available, but in practice the number of usable addresses is significantly less, causing a potential shortage of IP addresses. (Details from IANA.) While the number of web sites (and associated domain names) remains small relative to the number of IP addresses, allocating a dedicated IP address to each site is seen as wasteful, especially when hundreds or even thousands of web sites can in many instances share a single web server. In addition, reconfiguring a web server to add additional IP addresses is a relatively complicated task -- one that, on many operating systems, temporarily disables network connectivity and temporarily renders existing web sites unreachable.
Combining these administrative difficulties with concern as to a possible shortage of IP addresses and a perceived need to be more conservative in IP address allocations, the Internet's technical community devised a means of reducing the number of IP addresses required to host web content. Under version 1.1 of the HTTP specification (section 5.1.2), many web sites can share a single IP address without facing the file confusion problems described above. This is possible because when a HTTP 1.1 browser sends a request to a web server, its request bears the name not only of the requested file but also of the requested web site -- not just "give me /index.html" but "give me the /index.html file on the server http://www.yahoo.com." While this configuration is known by a number of names, including "virtual hosting" and "name-based hosting," the remainder of this document calls it "IP sharing."
HTTP 1.1 was adopted in 1999 and has since become the prevalent standard, supported by all recent web browsers and servers. Indeed, HTTP 1.1's IP sharing has been mandated by authorities that assign IP addresses (1, 2, 3), meaning that operators of commercial web hosting facilities must use IP sharing in order to receive IP addresses necessary to connect to the Internet.Internet Filtering
Although IP sharing has become standard practice, widely supported by all recent web browsers and web servers, IP sharing nonetheless interacts unpredictably with certain efforts to filter the Internet. This section provides an overview of filtering systems and their technical design, necessary to understanding the effect of IP sharing on the accuracy and granularity of Internet filtering.
Since the rise of widespread Internet use, a number of governments, companies, and private citizens have expressed concern as to certain controversial content available on the Internet. In the United States, controversial content often consists of sexually-explicit images. In Europe, hate speech is often of greatest concern. In parts of Asia, political speech is sometimes targeted. Concerned parties sometimes seek to remove such content from the Internet altogether, but when content is hosted on a server in a distant country, jurisdictional issues make enforcement impractical. Accordingly, some governments and private parties have implemented filtering systems -- intended to block controversial content before it arrives at a user's computer.
In certain countries, Internet connections are designed in a way that passes all communications through central facilities, directly facilitating centralized filtering. For example, Saudi Arabia has designed its network in precisely this way. (See the Saudi statement on the design of their domestic network, and see also the author's prior work documenting specific sites blocked in Saudi Arabia.) This centralized filtering design allows the use of proxy servers which can review all web requests and block access to sites deemed unacceptable. Proxy servers can be designed to filter at the level of specific web sites -- even when multiple web sites share IP addresses, as described above -- and can even block particular pages on sites that otherwise remain accessible.
However, proxy-based implementations are less practical in the US and in Europe, where networks tend to be decentralized, featuring a multitude of links between ISPs. In this network design, it is less clear where to put a central proxy server, for the network does not create any obvious central point of control. Huge traffic volumes also make proxy servers less practical; hundreds or thousands of proxy servers would be required to filter a large network without a degradation in performance, but so many servers would be costly and burdensome to install and maintain. Accordingly, when governments order filtering in the US, the most obvious approach -- with lowest cost and fastest implementation time -- is to configure network infrastructure (typically, routers) to deny requests on the basis of the IP address of the remote web site.
Within the framework of filtering on the basis of web site IP address, it is problematic for many web sites to share a single IP address: If filtering is to operate at the level of IP address, all web sites sharing that IP address will necessarily be blocked even if only a single site (or portion of a site, i.e. a particular page) is specifically targeted for filtering. This problem is known to affect filtering in China (see the author's prior research, Empirical Analysis of Internet Filtering in China) and in Vietnam. In 2002, the state of Pennsylvania passed a law that requires ISPs to filter designated web sites found to distribute child pornography; ISPs have responded by implementing blocks on the basis of web site IP address (cite), and Pennsylvania (and, for many affected ISPs, their entire US or North American networks) has thereby begun to use content filtering by IP address.
In recent data collection efforts, the author has obtained the IP address associated with the default web site in each current COM, NET, and ORG domain. By convention, this host bears the name "www" -- so the default web site within the yahoo.com domain is www.yahoo.com. The author tabulated the resulting information in a database, and the links and analysis below reflect a portion of the results.
This work is similar in motivation to the Internet Software Consortium's Domain Survey. However, the specific methodology varies: ISC's Domain Survey begins by obtaining all IP addresses that, according to the DNS's reverse lookup records, host at least one domain name; ISC then conducts an ordinary DNS lookup on each such domain name. (Details on ISC's methodology.) ISC's approach includes all hosts properly listed in DNS reverse lookup records, even hosts that provide no web sites, that are associated with web sites on non-default host names, or that are associated with host names in TLDs other than COM, NET, and ORG. However, ISC's approach assumes completeness of the reverse DNS, a facility that is frequently misconfigured, particularly so in the area of web sites using IP sharing.
The pages linked below provide the top web hosts -- those that were found in testing of December 2002 to host 200 or more distinct domain names. The "with listings" pages provide up to 25 specific web sites hosted on each site. When available, each host name's listing includes its DNS reverse lookup value and the title of its default web page (when the host is accessed by IP address, not by domain name). The 6,673 IP addresses listed below host web sites on a total of 20,113,430 distinct domain names.
Top web hosts: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Top web hosts with domain listings: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Analysis considers only the default web sites in active domains, as listed in the zone files published by.COM, .NET, and .ORG registries in December 2002. Reporting therefore undercounts hosts offering content in new TLDs (BIZ, INFO, NAME) and in ccTLDs. Reporting also omits domains with non-default host names (other than "www"). Analysis considers only host names that were actually operational (resolving to valid IP addresses) as of December 2002. When a web site is hosted on multiple servers (as via DNS load balancing), analysis reports only one of the associated servers, and the associated servers are therefore likely to be undercounted in the resulting analysis.
Analysis and Summary Statistics
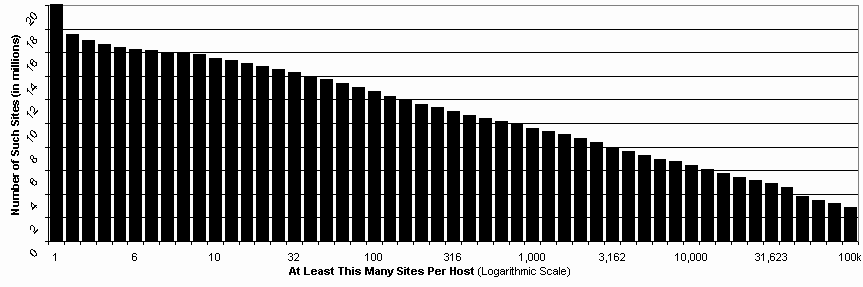
Most web sites are hosted on servers that host multiple web sites. Analysis considers a total of 20,113,430 distinct web sites that were, as of December 2002, each the operational default web host in a current COM, NET, or ORG domain. Of these sites, 17,568,104 (87.3%) resided on a server that hosted two or more distinct default COM, NET, and ORG names in total; 16,482,601 (81.9%) a server with at least five; 15,087,978 (75.3%) with at least 20; 14,013,627 (69.8%) with at least 50. The graph below shows the total of number of sites (vertical axis) hosted on servers with at least a given number of total sites (horizontal axis; note logarithmic scale).
A Taxonomy of Web Servers with Many Associated Web Sites. Some of the web servers listed above host hundreds of thousands of web sites, and thousands of servers each host thousands of web sites. With so many sites hosted on large web servers, it is desirable to separate servers into categories reflecting their usage and the types of content they respectively offer. The author suggests a four-step spectrum ordered according to the amount of unique content available on each site:
Heterogeneity of Sites Sharing IP Addresses. The practical effect of IP sharing on Internet filtering efforts depends on the heterogeneity of sites sharing IP addressees: If all sites on a given IP address provide similar or related content, then filtering of that IP address is less likely to mistakenly block non-controversial content than if sites on an Within the four-prong categorization identified above, servers in categories one and two tend to offer limited content that is highly homogenous. However, servers in categories in three and four feature a broad mixture of content. The author conducted a limited manual review of sites hosted on these latter categories, concluding that these servers typically host a wide mix of content without any substantive unifying theme. Analysis suggests, and prior experience confirms, that it is not atypical for a single web server to host a mixture of sites that are sexually explicit and sites that are not. John Morris of the Center for Democracy & Technology has reviewed portions of my data, posted to this site, and has flagged numerous specific IP addresses hosting both sexually-explicit and non-explicit sites; he describes one such address in an attachment to his recent testimony as to the problems of IP-based filtering in Maryland.
The results detailed above reflect that sharing of IP addresses is prevalent -- used by 87.3% of active COM, NET, and ORG web sites. In addition, IP sharing is substantial: More than two third of active COM, NET, and ORG web sites share their respective web servers with 50 or more other web sites.
At the same time, filtering by IP address is also prevalent and seems to be increasing in usage. Such filtering is already used in China and Vietnam, and the author's prior research indicates that IP filtering is one filtering method used by many commercial filters installed in libraries and public schools. Finally, under a 2002 law, the Attorney General of Pennsylvania has recently begun to order ISPs doing business in that state to "disable access" to designated sites found to offer child pornography; most ISPs receiving such orders reportedly use router-level filtering to disable access to the affected IP address (reference, news coverage), even though that IP's server might contain scores of additional web sites and thousands of specific web pages without child pornography. Related work by the Center for Democracy & Technology considers the Constitutional and policy implications of this law, and in September 2003 CDT filed suit to challenge the constitutionality of the law.
This analysis and prior experience both suggest that filtering on the basis of IP address is bound to lead to overblocking -- unintentional filtering of sites not targeted by filter operators. This is so for at least two distinct reasons: First, those who set filtering criteria typically cannot know what other sites share a web server with a site they deem unacceptable or, indeed, whether any other sites share that web server. Inconvenient as it may be, the Internet's domain name system simply is not organized in a way that make it easy to obtain this information. The author's methods of making this determination are novel and, to the best of his knowledge, unique; filtering staff, be they in China or in Pennsylvania, are unlikely to have access to this information. Second, even if filtering staff knew what other content shared an IP address with controversial content, their technologically-imposed restriction to IP-based filtering means that a decision to block the targeted content requires blocking the other content on that IP address. Recognizing this problem, filtering efforts in China seem to be moving from IP-based filtering towards URL-based filtering (see discussion in the author's prior research on this subject). However, as discussed above, sophisticated filtering systems are particularly difficult to implement in a complex network design like that in the United States; Worldcom recently told the Pennsylvania Attorney General's Office that "it is not technically feasible ... to block a site based on its URL."
Notwithstanding the overbroad blocking associated with IP-based filtering, those who dislike efforts at Internet filtering may find more focused filtering even more problematic. As the author describes in a recent op-ed in the South China Morning Post, "These new filtering abilities alter the balance between ... censors and users. ... [T]raditional filtering methods were bound to provoke outrage since they led to over-blocking of popular web sites. But ... more focused blocking may not elicit indignation or even notice. 'China blocks 100 dissident web sites' is a far less incendiary headline than 'China blocks one million blogs.'"
Beyond their implications for router-based filtering, shared IP addresses can also present difficulties for commercial Internet filtering applications. While commercial proxy implementations are in principle capable of restricting access in a way that properly takes account of the many web sites that may share a single IP address, extensive casual reports and the author's prior research both reflect that some filters nonetheless fail to do so. This may reflect design errors, cost-cutting measures, or attempts to block all sources of sexually-explicit content even at the expense of blocking non-pornographic sites. (This final factor may be especially prevalent when providers of sexually-explicit content register a large volume of domain names, such that filtering software designers find it easier and more effective to block the entire server at issue rather than to find and categorize scores of domain-specific listings.) The author discusses this subject in greater detail in his prior Sites Blocked by Internet Filtering Applications (Initial Expert Report, page 25), and Seth Finkelstein discusses it in "CyberPatrol - 247 bans for the price of 1". In future work, the author hopes to quantify the extent to which providers of commercial Internet filtering software rely on IP-based filtering rather than domain-based filtering.
Partial support for this project was provided by the Berkman Center for Internet & Society at Harvard Law School. The author seeks additional financial support to continue this and related projects. Please contact the author with suggestions.
The author maintains additional data as to the connections between web sites and their respective IP addresses. The author has also developed high-speed software systems to gather updates of this data as desired. Collaborations are welcomed with those who have research, legal, policy, or other interests in these results and methods.
Last Updated: September 12, 2003 - Sign up for notification of major updates and related work.